前段时间我写过一篇 GLM-5.1 对比 Qwen 3.6 Plus 的文章,当时两者打得难解难分。但就在最近,阿里云通义千问团队放出了大招——Qwen 3.6 Max (Preview) 版本。而智谱 AI 的 GLM 5.1 依然是目前的顶流选手。
今天,我们将抛开官方的营销话术,直接拆解最新的 12 项核心 Benchmark 跑分图表。这篇文章将详细讲解每一个跑分子项的真实含义,并对比这两位国产大模型天花板的硬实力。
总体概览:神仙打架,各有千秋 链接到标题
从官方放出的雷达图/柱状图来看,Qwen 3.6 Max (Preview) 展现出了极其恐怖的统治力,在 12 项测试中拿下了 8 项第一(对比 GLM 5.1)。但 GLM 5.1 并非没有还手之力,它在极其硬核的“真实软件工程 (SWE-bench)”和“高价值任务 (GDPval)”中实现了反超。
为了更清晰地对比,我将这 12 个指标分为了三大类:基础知识与推理、Agent智能体与工具调用、高阶代码能力。
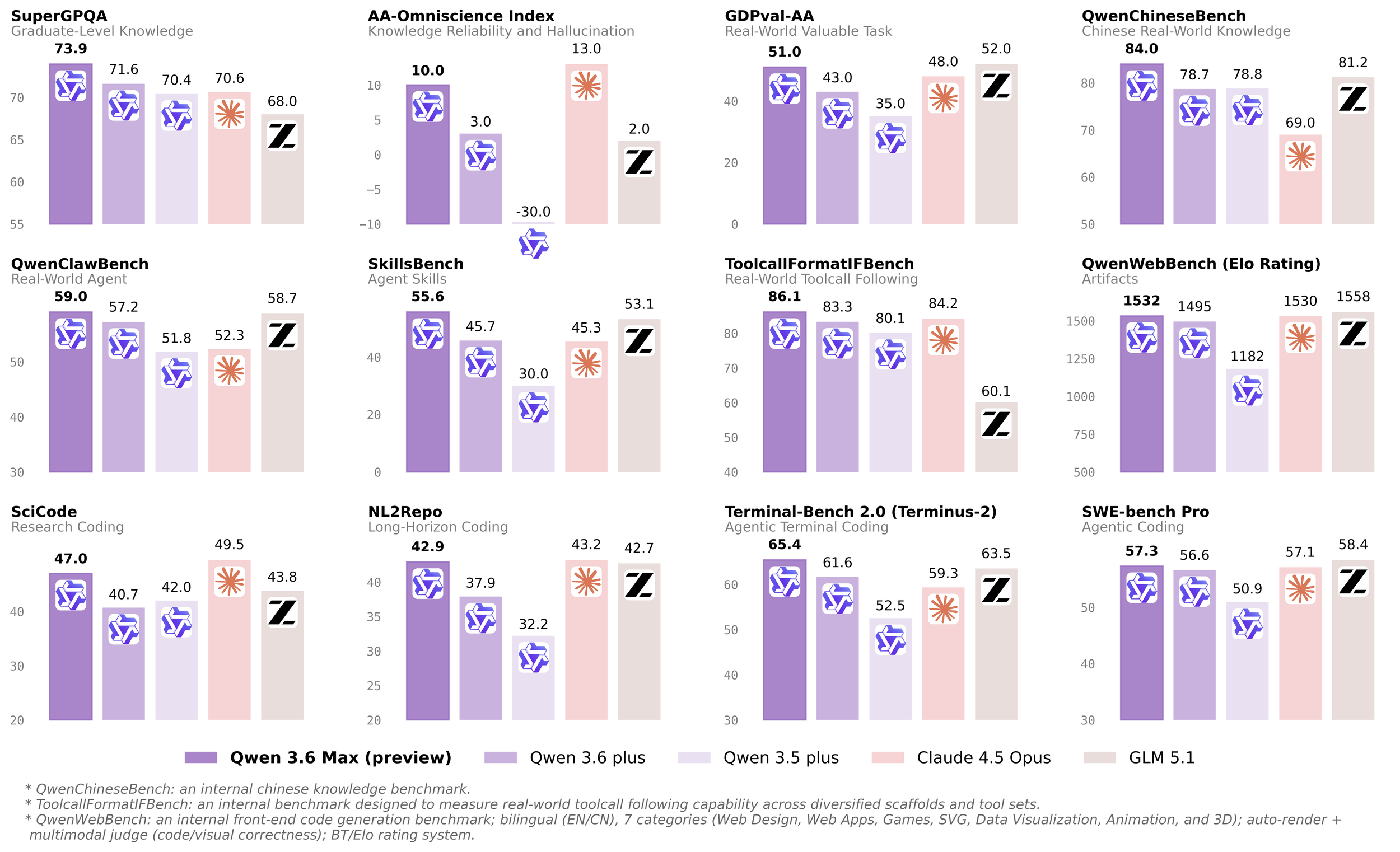
一、 基础知识与推理能力 (Knowledge & Reasoning) 链接到标题
这一维度主要考察模型的“智商”、知识储备的广度与深度,以及是否容易胡说八道。
1. SuperGPQA (Graduate-Level Knowledge) 链接到标题
- 指标含义:研究生级别的专业知识问答。这不仅要求模型有海量的知识库,还要求具备极强的复杂逻辑推理能力,通常涉及物理、化学、生物等高难度学科。
- 对比结果:Qwen 3.6 Max (73.9) vs GLM 5.1 (68.0)
- 分析:在极端复杂的学术问题上,Qwen 3.6 Max 展现了明显的优势,拉开了近 6 分的差距。这说明在处理高阶专业任务时,Qwen 的底层基础更加扎实。
2. AA-Omniscience Index (Knowledge Reliability and Hallucination) 链接到标题
- 指标含义:知识可靠性与幻觉指数。得分越高,说明模型越诚实,越不容易产生“一本正经地胡说八道”(幻觉)的现象。
- 对比结果:Qwen 3.6 Max (10.0) vs GLM 5.1 (2.0)
- 分析:这是 Qwen 碾压的一局(虽然 Claude 4.5 Opus 以 13.0 领跑,但在此我们只对比 Qwen 和 GLM)。GLM 5.1 在这个榜单上得分仅为 2.0,这意味着在需要绝对严谨的场景下,Qwen 3.6 Max 提供的信息可信度远高于 GLM 5.1。
3. QwenChineseBench (Chinese Real-World Knowledge) 链接到标题
- 指标含义:中文真实世界知识(Qwen内部测试集)。主要考察模型对中国本土文化、常识、时事以及中文特有语境的理解。
- 对比结果:Qwen 3.6 Max (84.0) vs GLM 5.1 (81.2)
- 分析:作为两家中国头部企业,中文能力都很顶尖。由于是 Qwen 的内部榜单,Qwen 占据主场优势拿下 84.0,但 GLM 5.1 依然咬得很死(81.2),两者在日常中文交互中体感差距应该不大。
二、 Agent 智能体与工具调用能力 (Agent & Tool Use) 链接到标题
大模型正在从“对话框”走向“行动派”,这一部分考察它们作为 Agent 解决实际问题的能力。
4. ToolcallFormatIFBench (Real-World Toolcall Following) 链接到标题
- 指标含义:真实世界工具调用格式遵循(Qwen内部测试集)。考察模型在使用外部 API、插件时,输出的 JSON 或特定格式是否严格符合规范,不报错。
- 对比结果:Qwen 3.6 Max (86.1) vs GLM 5.1 (60.1)
- 分析:巨大差距! Qwen 3.6 Max 在工具调用的稳定性上取得了压倒性胜利。如果你是开发者,使用 Qwen 构建多 Agent 系统或调用复杂 API 时,解析错误的概率会比 GLM 5.1 低非常多。
5. SkillsBench (Agent Skills) 链接到标题
- 指标含义:智能体基础技能。衡量模型在执行多步骤任务时的规划、反思、分解目标等底层 Agent 技能。
- 对比结果:Qwen 3.6 Max (55.6) vs GLM 5.1 (53.1)
- 分析:Qwen 小胜。两者都具备优秀的 Agent 基础能力,Qwen 在复杂规划上略微领先。
6. QwenClawBench (Real-World Agent) 链接到标题
- 指标含义:真实世界智能体表现。这是一个综合性的日常任务测试,模拟人类在浏览器操作、文件处理等真实场景中的表现。
- 对比结果:Qwen 3.6 Max (59.0) vs GLM 5.1 (58.7)
- 分析:不相上下。在常规的 Agent 任务中,两者的表现几乎完全一致。
7. GDPval-AA (Real-World Valuable Task) 链接到标题
- 指标含义:具有真实商业/经济价值的任务。这是一个偏向实用性和落地价值的榜单,考察模型解决能真正“产生价值”的问题的能力。
- 对比结果:Qwen 3.6 Max (51.0) vs GLM 5.1 (52.0)
- 分析:GLM 5.1 扳回一局。 智谱在 B 端商业化落地方面一直经验丰富,这项指标的反超说明 GLM 5.1 在处理某些特定商业逻辑或高价值工作流时,反而比 Qwen 3.6 Max 更有效率。
三、 高阶代码能力 (Advanced Coding) 链接到标题
现在的模型不仅要会写简单的排序算法,还要能接手整个项目。代码能力是检验大模型逻辑能力的试金石。
8. SWE-bench Pro (Agentic Coding) 链接到标题
- 指标含义:真实软件工程能力。这是目前最权威、最硬核的代码榜单之一。模型需要像真实程序员一样,阅读 Github 仓库中的海量代码,定位 Bug 并提交可运行的 PR (Pull Request)。
- 对比结果:Qwen 3.6 Max (57.3) vs GLM 5.1 (58.4)
- 分析:GLM 5.1 获胜! 这是一个含金量极高的反超。在解决真实世界的复杂软件工程 Bug 时,GLM 5.1 的代码理解和工程架构能力略强于 Qwen 3.6 Max。
9. QwenWebBench (Elo Rating - Artifacts) 链接到标题
- 指标含义:前端代码生成与可视化(内部测试集)。类似于 Claude 的 Artifacts 功能,考察模型生成 Web 网页、数据可视化、SVG、小游戏等并直接渲染的能力。
- 对比结果:Qwen 3.6 Max (1532) vs GLM 5.1 (1558)
- 分析:最令我意外的结果! 在 Qwen 自家的前端生成测试集中,GLM 5.1 竟然以 1558 的 Elo 分数踢馆成功,超越了 Qwen 3.6 Max。这说明 GLM 5.1 在 UI 设计、前端框架(React/Vue等)的掌握上极其出色。
10. SciCode (Research Coding) 链接到标题
- 指标含义:科研与科学计算代码。考察模型编写复杂数学、物理模拟、数据科学和机器学习算法代码的能力。
- 对比结果:Qwen 3.6 Max (47.0) vs GLM 5.1 (43.8)
- 分析:Qwen 3.6 Max 扳回一城。结合前面的 SuperGPQA 得分,可以看出 Qwen 在“学术科研+代码实现”这一垂直领域优势明显。
11. NL2Repo (Long-Horizon Coding) 链接到标题
- 指标含义:自然语言到完整代码仓库(长逻辑链编程)。给一句需求,模型需要规划目录结构并生成包含多个文件的完整项目。
- 对比结果:Qwen 3.6 Max (42.9) vs GLM 5.1 (42.7)
- 分析:极其焦灼,仅差 0.2 分,可以视为平手。两者都能很好地处理从 0 到 1 的项目生成。
12. Terminal-Bench 2.0 (Terminus-2) (Agentic Terminal Coding) 链接到标题
- 指标含义:终端命令行编程智能体。测试模型在 Linux 终端环境下的生存能力,包括执行 Shell 脚本、配置环境、在终端里 Debug 等。
- 对比结果:Qwen 3.6 Max (65.4) vs GLM 5.1 (63.5)
- 分析:Qwen 3.6 Max 胜出。对于经常需要让大模型接管服务器运维或自动化脚本的后端开发者来说,Qwen 是更好的选择。
总结与选型建议 链接到标题
看完这 12 项指标,我们可以得出以下结论:
Qwen 3.6 Max (Preview) 的核心标签是:“学术霸主”与“严谨的API执行者”。
- 优势:在极端困难的科研知识 (SuperGPQA, SciCode)、抗幻觉能力 (AA-Omniscience)、以及工具调用的格式稳定性 (ToolcallFormatIFBench) 上,Qwen 3.6 Max 展现了碾压级别的实力。
- 适用场景:学术研究辅助、复杂的后端命令行自动化、以及需要极高稳定性多步骤 API 调用的 Agent 开发。
GLM 5.1 的核心标签是:“实干工程师”与“前端大师”。
- 优势:虽然在学术和纯测试指标上略逊一筹,但 GLM 5.1 在解决真实商业问题 (GDPval-AA)、修复真实开源项目 Bug (SWE-bench Pro)、以及前端页面生成 (QwenWebBench) 上实现了极其亮眼的反超。
- 适用场景:企业内部业务流处理、替代初级程序员修 Bug(接入IDE Copilot)、以及快速产出 Web UI 原型(类似 Artifacts 场景)。
目前 Qwen 3.6 Max 仍处于 Preview 阶段,最终正式版的表现依然值得期待。但不可否认的是,这两家厂商已经代表了国产大模型在“逻辑推理”与“代码能力”上的最高水平,且已经能在诸多场景与 Claude 4.5 Opus 互有胜负。
你更看好哪款模型?欢迎在评论区留下你的看法!
声明:以上数据基于公开的 Benchmark 对比图表(如 QwenChineseBench 等含官方内部测试集),实际体感可能因 Prompt 提示词工程和具体业务场景而有所不同。